Data Engineering Project
projects | | Links: Repository link

🚩 Goal
In this project, I design an ELT pipeline using Snowflake as the cloud data warehouse. I define my transformation pipelines in a dbt project, and orchestrate the pipelines using Airflow and Astronomer Cosmos.
The decision to use ETL or ELT informs subsequent considerations about data pipeline architecture and implementation.
This project showcases the ELT approach, which has grown in popularity with the advent of massively parallel processing databases and cloud infrastructure.
The crux of the ELT process is to load the data directly into your data warehouse, as opposed to maintaining a dedicated server responsible for processing and transforming your data.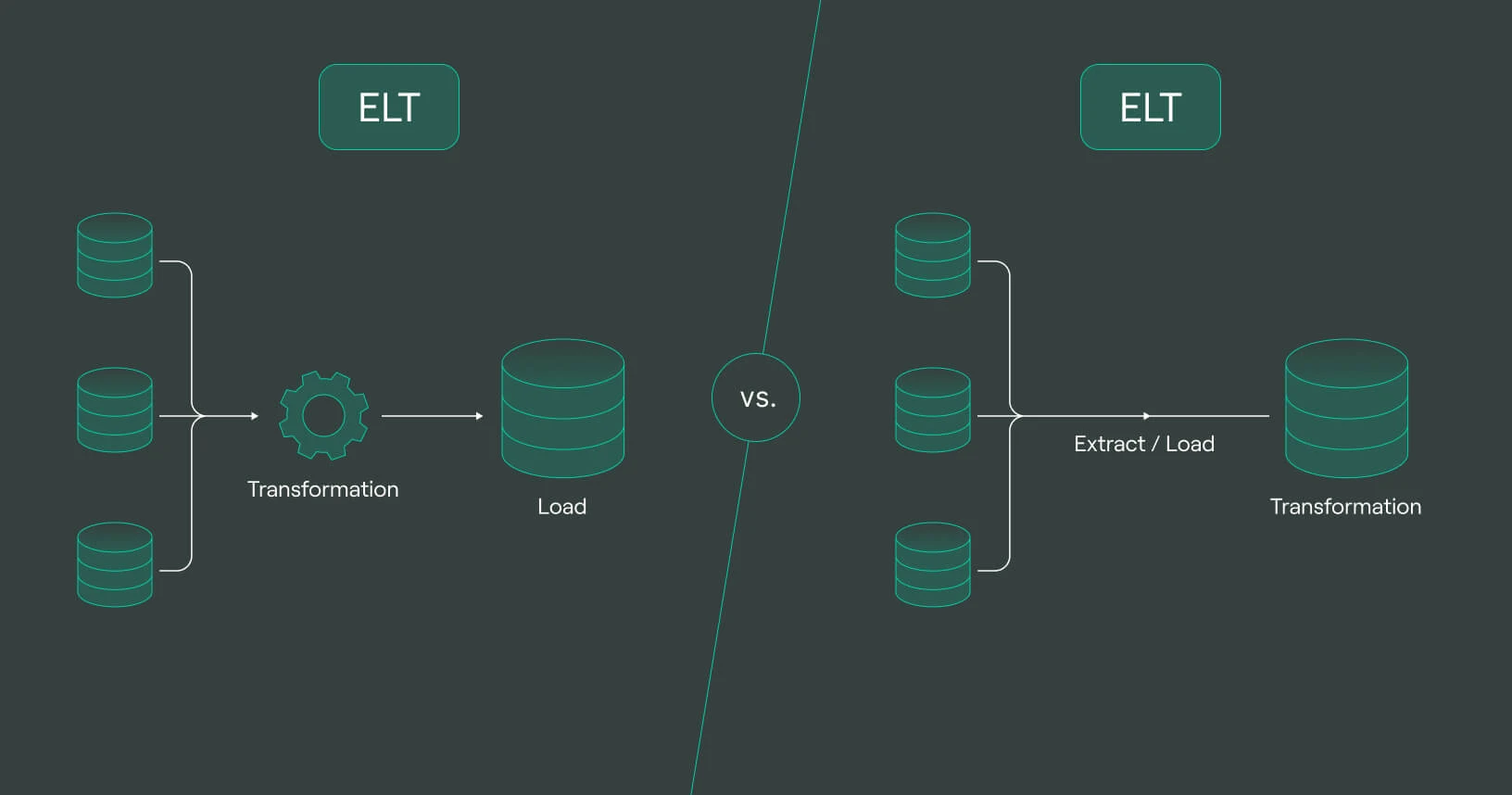
This key difference is ELT’s most compelling case - when data is loaded with minimal processing into the data warehouse, its raw state is retained, meaning that downstream pipelines can be recreated, rewritten, or dropped easily in response to changing business priorities.
When used in conjunction with tools like dbt, ELT shifts the responsibility of developing data pipelines to Analytics Engineers / Data Analysts, individuals who understand the business better than Data Engineers, but might not have the technical chops to write scalable, robust ETL code.
📊 Tools primer
Snowflake is a cloud data platform, which is a key component of the modern data stack. It supports transformation workloads written in SQL, along with a suite of other nifty features, such as autoscaling, a RESTful API, and extension to a broad ecosystem of 3rd party tools and technologies.
Airflow is an open source workflow management tool to orchestrate data engineering pipelines. To allow better visibility into the lineage of tasks, this project uses Astronomer Cosmos to integrate dbt and Airflow.
🖥️ TPC-H Data
The TPC-H benchmark is a widely recognised tool for evaluating the performance of data processing systems. It consists of a suite of decision support queries based on a multi-table schema.
I chose to build the project on the TPC-H dataset due to the following reasons:
Realism: TPC-H simulates real-world business operations, entities, and relationships
Integration with Snowflake: TPC-H data tables are available as sample data within Snowflake
Size: Because of the size, building data pipelines from the TPC-H data requires efficiency in data processing and transformation jobs
🖥️ Process
Further Reading
[1] A brief introduction to Airflow internals / architecture can be found here
[2] A more detailed comparison of ETL vs ELT can be found here